[NLP] 텍스트 벡터화 : TF-IDF 실습
2023. 11. 3. 10:42ㆍML&DL/NLP
[NLP] 텍스트 벡터화
벡터화 (Vectorization) 1. 신경망 사용하지 않을 경우 - 단어 : 원-핫 인코딩 - 문서 : Document Term Matrix, TF-IDF 2. 신경망 사용할 경우 - 단어 : 워드 임베딩 (Word2Vec, GloVe, FastText, Embedding layer) - 문서 : Doc2Vec
situdy.tistory.com
이전 글에서 설명한 TF-IDF 실습을 해보겠습니다
TF-IDF
- 문서의 벡터화 방법
- 인공 신경망을 이용하지 않음.
- 모든 문서에서 자주 등장하는 단어는 중요도가 낮다고 판단,
특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단
💻 실습
import pandas as pd
from math import log
문서 정의
# 4개의 문서
docs = [
'먹고 싶은 사과',
'먹고 싶은 바나나',
'길고 노란 바나나 바나나',
'저는 과일이 좋아요'
]
# vocab 구축
vocab = list(set(w for doc in docs for w in doc.split()))
vocab.sort()print(vocab)
['과일이', '길고', '노란', '먹고', '바나나', '사과', '싶은', '저는', '좋아요']
# 총 문서의 수
N = len(docs)
print('총 문서의 수', N)총 문서의 수 4
TF, IDF, TF-IDF 값을 구하는 함수 정의
# TF를 구하는 함수
def tf(t, d):
return d.count(t)# IDF를 구하는 함수
def idf(t):
df = 0
for doc in docs:
df += t in doc
return log(N/(df+1))# TF와 IDF의 값을 곱하는 함수
def tfidf(t, d):
return tf(t,d)* idf(t)
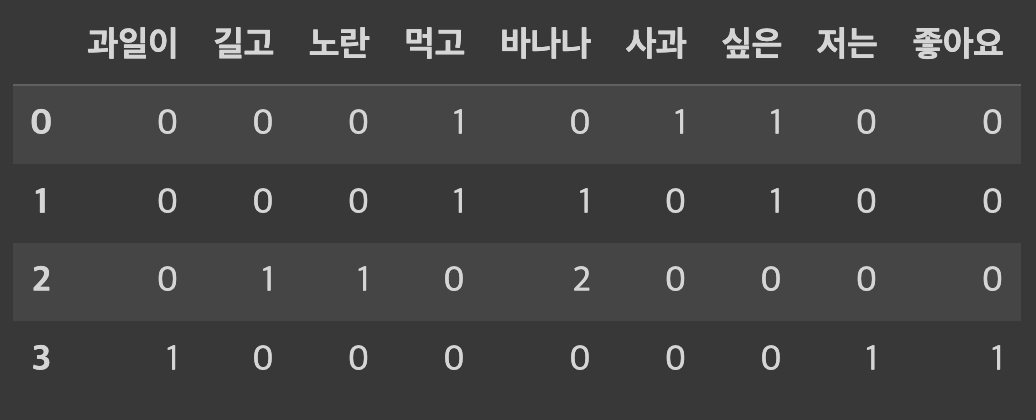
TF 값 구하기
result = []
# 각 문서에 대해서 아래 연산을 반복
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
# tf 함수를 호출 : TF 값을 계산
result[-1].append(tf(t, d))
tf_ = pd.DataFrame(result, columns = vocab)
IDF 값 구하기
result = []
# 각 단어에 대해서 idf값을 계산
for j in range(len(vocab)):
t = vocab[j]
# idf 함수를 호출 : IDF 값을 계산
result.append(idf(t))
# IDF 출력
idf_ = pd.DataFrame(result, index=vocab, columns=["IDF"])
idf_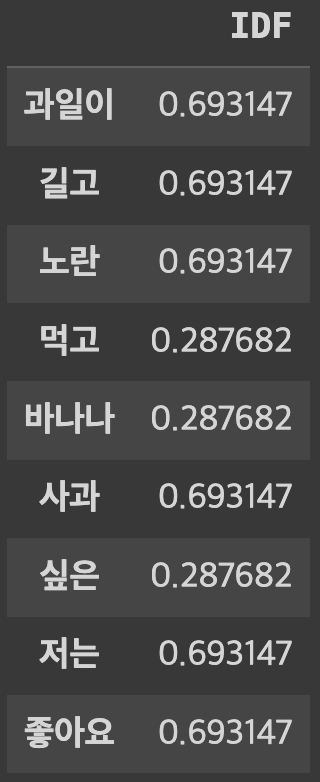
TF-IDF 행렬
- TF * IDF 한 값
result = []
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
# tfidf 함수를 호출 : TF-IDF 값 계산
result[-1].append(tfidf(t,d))
# TF-IDF 행렬
tfidf_ = pd.DataFrame(result, columns = vocab)
tfidf_
sklearn를 사용해서 DTM & TF-IDF 를 구하기
- CountVectorizer : DTM 구하기
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
vector = CountVectorizer()
# 코퍼스로부터 각 단어의 빈도수를 기록
print(vector.fit_transform(corpus).toarray())
# 각 단어와 맵핑된 인덱스 출력
print(vector.vocabulary_)

- TfidfVectorizer : TF-IDF 구하기
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'you know I want your love',
'I like you',
'what should I do ',
]
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.transform(corpus).toarray())
print(tfidfv.vocabulary_)
코사인 유사도
- 벡터간의 유사도를 구하는 방법
- -1 ~ 1 사이의 값을 가진다
-> 1에 가까울수록 일치하는 것
import numpy as np
from sklearn.metrics.pairwise import cosine_similaritydoc1 = np.array([[0,1,1,1]])
doc2 = np.array([[1,0,1,1]])
doc3 = np.array([[2,0,2,2]])
print('문서 1과 문서2의 유사도 :',cosine_similarity(doc1, doc2))
print('문서 1과 문서3의 유사도 :',cosine_similarity(doc1, doc3))
print('문서 2와 문서3의 유사도 :',cosine_similarity(doc2, doc3))
-> 문서 2와 3은 완전 일치한다

'ML&DL > NLP' 카테고리의 다른 글
| [NLP] 시퀀스 모델 - RNN, LSTM, GRU (0) | 2023.11.06 |
|---|---|
| [NLP] 텍스트 벡터화 : 워드 임베딩(Word embedding) 실습 (1) | 2023.11.03 |
| [NLP] 텍스트 벡터화 (0) | 2023.11.03 |
| [NLP] 데이터 전처리 - 정수 인코딩 / 패딩 실습 (0) | 2023.11.02 |
| [NLP] 데이터 전처리 - 정제 / 정규화 (0) | 2023.09.27 |