2023. 11. 27. 15:10ㆍML&DL/CV
[Food Object Detection]

목표
YOLOv8n 을 사용하여 10개의 Food 클래스를 실시간으로 Object Detection 해보기
데이터셋
- COCO dataset 중 val2017 사용
[Computer Vision] COCO 데이터셋
COCO Dataset https://cocodataset.org/#home COCO - Common
클래스
['banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake']
개발 환경
* Colab
💻 실습
* 데이터
- 데이터셋 다운로드 - COCO dataset의 val2017만 사용
!wget http://images.cocodataset.org/zips/val2017.zip
!wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip- 데이터셋 압축 풀기
!unzip val2017.zip -d /content/drive/MyDrive/datasets/coco
!unzip annotations_trainval2017.zip -d /content/drive/MyDrive/datasets/annotations
* json 파일 살펴보기
from pycocotools.coco import COCO
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
dataDir='..'
dataType='val2017'
annFile='/content/drive/MyDrive/Computer_Vision/datasets/annotations/annotations/instances_val2017.json'.format(dataDir,dataType)
# initialize COCO api for instance annotations
coco=COCO(annFile)
* 카테고리 출력
cats = coco.loadCats(coco.getCatIds())
nms=[cat['name'] for cat in cats]
print('COCO categories: \n{}\n'.format(' '.join(nms)))
nms = set([cat['supercategory'] for cat in cats])
print('COCO supercategories: \n{}'.format(' '.join(nms)))
COCO categories:
person bicycle car motorcycle airplane bus train truck boat traffic light fire hydrant stop sign parking meter bench bird cat dog horse sheep cow elephant bear zebra giraffe backpack umbrella handbag tie suitcase frisbee skis snowboard sports ball kite baseball bat baseball glove skateboard surfboard tennis racket bottle wine glass cup fork knife spoon bowl banana apple sandwich orange broccoli carrot hot dog pizza donut cake chair couch potted plant bed dining table toilet tv laptop mouse remote keyboard cell phone microwave oven toaster sink refrigerator book clock vase scissors teddy bear hair drier toothbrush
COCO supercategories:
food appliance kitchen animal accessory person outdoor furniture sports vehicle indoor electronic
* Food 카테고리 ID 출력
target_categories = ['banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake']
for category_name in target_categories:
cat_ids = coco.getCatIds(catNms=[category_name])
if cat_ids:
cat_id = cat_ids[0] # Assuming there is only one category with the given name
print(f"Category: {category_name}, ID: {cat_id}")
else:
print(f"Category '{category_name}' not found in the COCO dataset.")* Food 객체를 포함하는 json 파일 만들기
import os
import json
from pycocotools.coco import COCO
def filter_coco_data(coco, class_names):
filtered_images = []
filtered_annotations = []
for class_name in class_names:
cat_ids = coco.getCatIds(catNms=[class_name])
img_ids = coco.getImgIds(catIds=cat_ids)
ann_ids = coco.getAnnIds(catIds=cat_ids)
images = coco.loadImgs(ids=img_ids)
annotations = coco.loadAnns(ids=ann_ids)
filtered_images.extend(images)
filtered_annotations.extend(annotations)
return filtered_images, filtered_annotations
# COCO 데이터셋 경로와 특정 클래스명을 설정합니다.
data_dir = '/content/drive/MyDrive/Computer_Vision/datasets/coco'
data_type = 'val2017'
annFile='/content/drive/MyDrive/Computer_Vision/datasets/annotations/annotations/instances_val2017.json'
coco = COCO(annFile)
# 원하는 클래스명을 리스트에 추가하세요.
SUBCLASS = ['banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake']
filtered_images, filtered_annotations = filter_coco_data(coco, SUBCLASS)
# 새로운 JSON 파일을 생성합니다.
filter_name = "_".join(SUBCLASS)
new_ann_file ='/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/food.json'
with open(new_ann_file, 'w') as f:
json.dump({
'images': filtered_images,
'annotations': filtered_annotations,
'categories': coco.loadCats(coco.getCatIds())
}, f)
* food.json을 이용해 food 객체를 포함한 image, label 폴더 만들기
category_ids = [52, 53, 54, 55, 56, 57,58, 59, 60, 61]
# 새로운 mapping 딕셔너리 생성
mapping = {category_ids[i]: i for i in range(len(category_ids))}import shutil
import os
def convert_coco_to_yolo(coco, annotations, img_dir, output_dir, mapping=mapping):
# 해당 카테고리와 클래스 ID 매핑
yolo_labels_dir = os.path.join(output_dir, 'labels')
yolo_images_dir = os.path.join(output_dir, 'images')
os.makedirs(yolo_labels_dir, exist_ok=True)
os.makedirs(yolo_images_dir, exist_ok=True)
for ann in annotations:
img = coco.loadImgs(ids=[ann['image_id']])[0]
img_width, img_height = img['width'], img['height']
x, y, width, height = ann['bbox']
# Normalize bbox coordinates
x_center = (x + width / 2) / img_width
y_center = (y + height / 2) / img_height
width /= img_width
height /= img_height
# Write YOLO label file
label_file = os.path.join(yolo_labels_dir, f"{img['file_name'].replace('.jpg', '.txt')}")
with open(label_file, 'a') as f:
f.write(f"{mapping[ann['category_id']]} {x_center} {y_center} {width} {height}\n")
# Copy the image file to YOLO images folder
src_img_file = os.path.join(img_dir, img['file_name'])
dst_img_file = os.path.join(yolo_images_dir, img['file_name'])
shutil.copyfile(src_img_file, dst_img_file)
# 원본 이미지 경로와 변환된 데이터를 저장할 경로를 설정합니다.
img_dir = os.path.join(data_dir, data_type)
output_dir = '/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection'
convert_coco_to_yolo(coco, filtered_annotations, img_dir, output_dir)* train/val/test 나누기
import os
import shutil
from sklearn.model_selection import train_test_split
# 원래 데이터셋이 있는 폴더 경로
image_folder = "/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/images"
label_folder = "/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/labels"
# 목표 폴더 경로
target_folder = "/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/training_dataset/"
os.makedirs(target_folder, exist_ok=True)
# 훈련, 검증, 테스트 비율
train_ratio = 0.8
val_ratio = 0.1
test_ratio = 0.1
# 모든 이미지 파일 가져오기
all_images = os.listdir(image_folder)
# 이미지와 텍스트 파일을 같이 나누기
train_images, rest_images = train_test_split(all_images, test_size=(val_ratio + test_ratio), random_state=42)
val_images, test_images = train_test_split(rest_images, test_size=test_ratio / (val_ratio + test_ratio), random_state=42)
# 각 세트에 해당하는 폴더 생성
for set_name, set_images in zip(['train', 'val', 'test'], [train_images, val_images, test_images]):
set_folder = os.path.join(target_folder, set_name)
os.makedirs(set_folder, exist_ok=True)
# 'images'와 'labels' 서브폴더 생성
os.makedirs(os.path.join(set_folder, 'images'), exist_ok=True)
os.makedirs(os.path.join(set_folder, 'labels'), exist_ok=True)
# 이미지 복사
for image in set_images:
src_image_path = os.path.join(image_folder, image)
dst_image_path = os.path.join(set_folder, 'images', image)
shutil.copy(src_image_path, dst_image_path)
# 텍스트 파일 찾기
label_file_name = image.replace('.jpg', '.txt')
src_label_path = os.path.join(label_folder, label_file_name)
dst_label_path = os.path.join(set_folder, 'labels', label_file_name)
shutil.copy(src_label_path, dst_label_path)
* yaml 파일 만들기
class_name = 'food'
config_txt = f'''
train: /content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/training_dataset/train/images
val: /content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/training_dataset/val/images
test: /content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/training_dataset/test/images
# Classes
names:
0: banana
1: apple
2: sandwich
3: orange
4: broccoli
5: carrot
6: hot dog
7: pizza
8: donut
9: cake
'''
with open(f"/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/{class_name}.yaml", 'w') as f:
f.write(config_txt)* 모델 학습
- yolov8n
from ultralytics import YOLO
# Create a new YOLO model from scratch
model = YOLO('yolov8n.yaml')
# Load a pretrained YOLO model (recommended for training)
model = YOLO('yolov8n.pt')
# Train the model using the 'vehicle.yaml' dataset for 150 epochs
results = model.train(data=f'/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/food.yaml', epochs=50)
# Evaluate the model's performance on the validation set
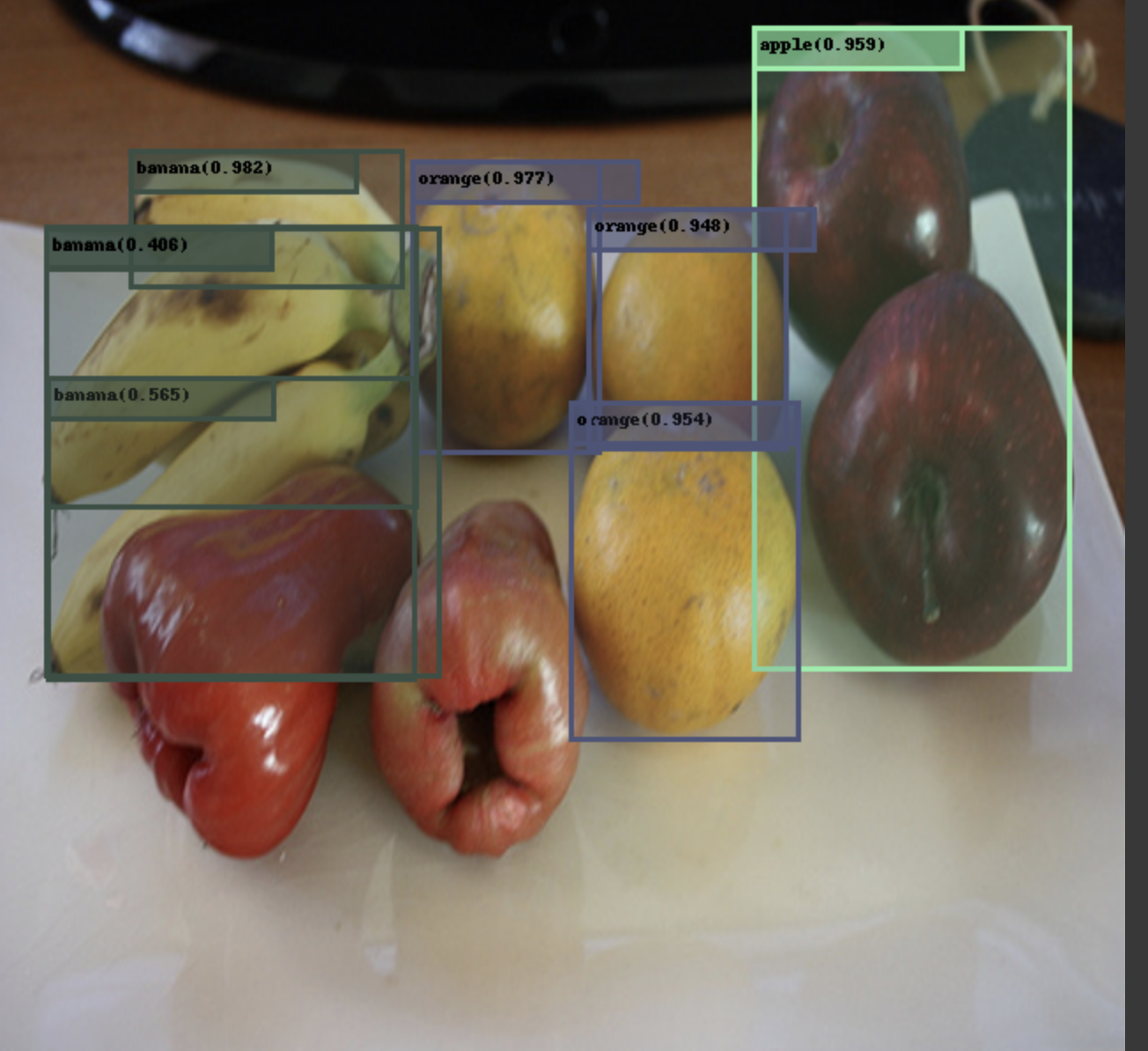
results = model.val()* 모델 테스트
from ultralytics import YOLO
from PIL import Image, ImageDraw, ImageFont
from glob import glob
import yaml
import numpy as np
import uuid
# Load a model
model = YOLO('/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/train2/weights/best.pt')
classes = ['banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake']
class_name = "food"
# Load images
filelist = glob(f"/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/training_dataset/test/images/*.jpg")
filelist = np.random.choice(filelist, size=1)
imgs = [Image.open(filename) for filename in filelist]
# Perform object detection on an image using the model
results = model(imgs)
def draw_bbox(draw, bbox, label, color=(0, 255, 0, 255), confs=None, size=12):
#font = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuMathTeXGyre.ttf", size)
draw.rectangle(bbox, outline=color, width =3)
def set_alpha(color, value):
background = list(color)
background[3] = value
return tuple(background)
background = set_alpha(color, 50)
draw.rectangle(bbox, outline=color, fill=background, width =3)
background = set_alpha(color, 150)
text = f"{label}" + ("" if confs==None else f"({conf:0.3})")
text_bbox = bbox[0], bbox[1], bbox[0]+len(text)*10, bbox[1]+25
draw.rectangle(text_bbox, outline=color, fill=background, width =3)
draw.text((bbox[0]+5, bbox[1]+5), text, (0,0,0))
color = []
n_classes = len(classes)
for _ in range(n_classes):
c = list(np.random.choice(range(256), size=3)) + [255]
c = tuple(c)
color.append(c)
from IPython.display import display, Image as IPImage
for i, (img, result) in enumerate(zip(imgs, results)):
img = img.resize((640, 640))
width, height = img.size
draw = ImageDraw.Draw(img, 'RGBA')
unique_id = str(uuid.uuid4())[:8] # 8자리의 고유 ID 생성
origin_filename = f"/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/origin_images/origin_image_{unique_id}.png"
img.save(origin_filename)
display(IPImage(filename=origin_filename))
for i, (img, result) in enumerate(zip(imgs, results)):
img = img.resize((640, 640))
width, height = img.size
draw = ImageDraw.Draw(img, 'RGBA')
result = result.cpu()
xyxys = result.boxes.xyxyn # box with xyxy format but normalized, (N, 4)
confs = result.boxes.conf # confidence score, (N, 1)
clss = result.boxes.cls # cls, (N, 1)
xyxys = xyxys.numpy()
clss = map(int, clss.numpy())
for xyxy, conf, cls in zip(xyxys, confs, clss):
xyxy = [xyxy[0]*width, xyxy[1]*height, xyxy[2]*width, xyxy[3]*height]
draw_bbox(draw, bbox=xyxy, label=classes[cls], color=color[cls], confs=confs, size=7
)
# 파일명을 고유하게 만들기 위해 i 대신 uuid 라이브러리 사용
unique_id = str(uuid.uuid4())[:8] # 8자리의 고유 ID 생성
img_filename = f"/content/drive/MyDrive/Computer_Vision/Food_ObjectDetection/output_images/output_image_{unique_id}.png"
img.save(img_filename)
display(IPImage(filename=img_filename))




'ML&DL > CV' 카테고리의 다른 글
| [GAN] CIFAR-10 데이터셋을 이용한 이미지 생성 모델 만들기 (0) | 2023.11.28 |
|---|---|
| [Computer Vision] GAN (Generative adversarial network) (0) | 2023.11.28 |
| [Object Detection] COCO 데이터셋을 이용한 교통수단 객체 인식 (0) | 2023.11.24 |
| [Computer Vision] COCO 데이터셋 (2) | 2023.11.24 |
| [Binary Classification] MRI 데이터셋을 사용한 뇌종양 음성/양성 모델 (0) | 2023.11.22 |