2023. 10. 4. 14:39ㆍADsP
정형 데이터
- KDD
- CRISP-DM
비정형 데이터
- 빅데이터 분석 방법론
[1] 데이터가 가지고 있는 특성을 파악하기 위해 해당 변수의 분포 등을 시각화하여 분석하는 분석 방식은 무엇인가?
1. 전처리 분석
2. 탐색적 자료 분석 (EDA)
3. 공간 분석
4. 다변량 분석
탐색적 자료 분석(EDA)
- 다양한 차원과 값을 조합해가며 특이한 점이나 의미 있느 사실을 도출하고 분석의 최종 목적을 달성해가는 과정으로 데이터의 특징과 내재하는 구조적 관계를 알아내기 위한 기법들의 통칭이다.
- 데이터 이해 단계, 변수생성 단계, 변수선택 단계에서 활용됨
EDA의 4가지 주제
- 저항성의 강조, 잔차 계산, 자료변수의 재표현, 그래프를 통한 현시성
- 전처리 분석: 데이터 전처리는 데이터를 정제하고 준비하는 단계로, EDA 이전에 데이터를 처리하고 정리하는 단계입니다.
- 공간 분석: 공간적 차원과 관련된 속성들을 시각화하는 분석으로 지도 위에 관련 속성들을 생성하고 크기,모양,선 굵기 등으로 구분하여 인사이트를 얻는다
- 다변량 분석: 다변량 분석은 여러 변수 간의 관계를 이해하고 모델링하는 분석 방법으로, EDA의 한 부분일 수 있지만 주로 변수 간의 상호 작용 및 영향을 파악하는 것에 중점을 둡니다.
[2] 데이터 마이닝의 모델링에 대한 설명이다.설명이 가장 잘못된 것은?
1. 데이터마이닝 모델링은 통계적 모델링이 아니므로 지나치게 통계적 가설이나 유의성에 집작 하지 말아야 한다.
2. 모델링 방법은 여러 가지가 있으므로 모델링 시 반드시 다양한 옵션을 줘서 모델링을 수행 하여 최고의 성과를 도출하여야 한다.
3. 분석데이터를 학습 및 테스트 데이터로 6:4, 7:3, 8:2 비율로 상황에 맞게 실시한다.
4. 성능에 집착하면 분석 모델링의 주목적인 실무 적용에 반하여 시간을 낭비할 수 있으므로 훈련 및 테스트 성능에 큰 편차가 없고 예상 성능을 만족하면 중단한다.
=> 충분한 시간이 있으면 다양한 옵션을 줘서 시도하는 것이고, 일정한 성과가 나오면 해석과 활용 단계로 진행할 수 있도록 의사 결정 해야 한다.
[3] 모델링 성능을 평가함에 있어, 데이터 마이닝에서 활용하는 평가 기준이 아닌 것은?
1. 정확도(Accurcay)
2. 리프트(Lift)
3. 디렉트 레이트(Detect Rate)
4. Throughput(처리율)
=> 처리량은 시뮬레이션 평가 지표
데이터마이닝 모델링 성능 평가 기준
- 정확도(Accuracy): 모델이 올바르게 예측한 샘플의 비율을 나타내는 지표로, 가장 일반적으로 사용되는 성능 평가 메트릭 중 하나입니다.
- 리프트(Lift): 주로 마케팅 및 클래스 불균형 문제에서 사용되는 지표로, 모델이 특정 이벤트의 발생 여부를 얼마나 잘 예측하는지를 평가합니다. (x축 = 사용된 데이터 셋의 비율, y축 = 타겟에 대한 예측도)를 그래프로 표현함. 모델의 예측이 100%에 도달하기 위해 필요한 데이터셋의 비율을 시각적으로 보여주는 차트.
- 디렉트 레이트(Direct Rate) = recall: 또 다른 클래스 불균형 문제에서 사용되는 지표로, 양성 클래스(예: 부도한 고객)를 얼마나 정확하게 예측하는지를 나타냅니다.
- 정밀도(Precision) : 정밀도는 모델이 양성 클래스로 예측한 샘플 중에서 얼마나 많은 것이 실제로 양성인지를 측정합니다.

정확도(Accuracy)
- 정확도는 모델이 만든 예측 중 올바른 예측의 비율을 나타냅니다. 모델이 얼마나 많은 정확한 예측을 했는지를 보여줍니다.

재현율(Recall)
- 재현율이란 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율입니다.
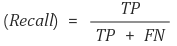
정밀도(Precision)
- 정밀도란 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율입니다.
[4] 탐색적 데이터 분석의 목적은 데이터를 이해하는 것이다. 다음 중 이에 대한 설명으로 가장 부적
절한 것은?
- 데이터에 대한 전반적인 이해를 통해 분석 가능한 데이터인지 확인하는 단계이다.
- 탐색적 데이터 분석 과정은 데이터에 포함된 변수의 유형이 어떻게 되는지를 찾아가는 과정이다.
- 데이터를 시각화하는 것만으로는 이상점(Outlier) 식별이 잘 되지 않는다.
- 알고리즘이 학습을 얼마나 잘 하느냐 하는 것은 전적으로 데이터의 품질과 데이터에 담긴 정보량에 달려 있다.
box plot 을 이용해 이상치 식별을 쉽게 할 수 있다.

[5] 아래의 그림은 데이터 처리 구조를 나타내고 있다. 그림에 대한 설명으로 잘못된 것은?
- 데이터를 분석에 활용하기 위해 데이터웨어하우스와 데이터마트에서 데이터를 가져 온다.
- 신규시스템이나 DW에 포함되지 않은 데이터는 기존 운영시스템(Legacy)에서 직접 데이터를 DW와 전처리 없이 바로 결합하면 된다.
- ODS는 운영데이터저장소로 기존 운영시스템의 데이터가 정제된 데이터이므로 DW나 DM과 결합하여 분석에 활용할 수 있다.
- 스테이지 영역에서 가져온 데이터는 정제되어 있지 않기 때문에 데이터를 전처리해서 DW나 DM과 결합하여 사용한다.
=> 신규 시스템이나 스테이징 영역의 데이터는 정제되지 않았기 때문에 정제하고 DW 나 DM과 결합해야한다.